1. Introduction
cheduling involves the timing and coordination of operations with the goal of obtaining a smooth rate of flow of goods or customers through the system, while attaining a high utilization of resources. Developing the production schedule in high-volume systems are often referred to as flow shop scheduling. In a multi-processor flow shop, there are multiple identical parallel machines in at least one of the multiple stages of operation. Some stages may have one machine, but at least one stage must have multiple machines. Each job is processed by one machine in each stage and it must go through one or more stages. Machines operating in parallel can be identical, uniform or unrelated.
Fuzzy set theory has been used to model this system. Recently, significant attention has been given to modeling scheduling problems within a fuzzy framework. This Fuzzy logic was introduced by Zadeh (1965). McCahone and Lee (1992) used fuzzy logic for job scheduling in flow shop. Chan et al. (1997) developed a fuzzy approach to operation selection. Tsujimura et al. (1993) showed that fuzzy set theory is useful in flow shop scheduling problems with uncertain processing times. Grabot and Geneste (1994) proposed a way to use fuzzy logic in order to build aggregated rules, to allow obtaining a compromise between the satisfactions of several criteria. Ishibuchi et al. (1994) formulated a fuzzy flow shop scheduling problem where the due-date of each job is given as a fuzzy set and the objective function was to maximize the minimum grade of satisfaction over given jobs. Hong and Wang (2000) showed that flexible flow shops can be considered as generalizations of simple flow shops. Petroni and Rizzi (2002) presented a fuzzy logic based tool intended to rank flow shop dispatching rules under multiple performance criteria. Kacem et al. (2002) proposed a Pareto approach based on the hybridization of fuzzy logic (FL) and evolutionary algorithms (EAs) to solve the flexible job-shop scheduling problem (FJSP).Yun, Y. S. (2002) proposed a new genetic algorithm (GA) with fuzzy logic controller (FLC) for dealing with preemptive job-shop scheduling problems (p-JSP) and nonpreemptive job-shop scheduling problems (np-JSP). Keung et al. (2003) The above proposed methods did not consider the fuzzy multi objective parallel flow shop problem and machine reliability based utilization during scheduling while considering criteria like critical ratio, completion time, processing complexity, mean time between maintenance and set up time. In this research, fuzzy rule based system is developed to address the uncertainty and satisfy the multiple objectives. This system provided the priority of each job by considering the information of processing time, due date, cost over time, profit over time, critical ratio, inventory level, etc. as appropriate fuzzy membership functions. On the other hand, the fuzzy inference system (FIS) provided the machine priority based on reliability and availability at each of the stages, considering mean time between failure (MTBF), mean time to repair (MTTR), mean time between shutdowns (MTBS), mean time between maintenance (MTBM), failure rate (FR) and set up time (ST).
2. II.
3. Problem Definition
In hybrid flow shop there may be a numbers of stages of processor and each stage has more than one identical machine. The machines are identical in a sense that, for a given stage the jobs need the same time to be processed on each machine. But the reliability and availability characteristics, i.e. mean time between failures, mean time to repair, mean time between shutdowns, mean time between maintenance, failure rate and set up time are different for each machine in a single stage.
Each job has to be processed in every stage. The priority of the jobs could be appraised by the values of their processing times, profit over time, due dates, cost over time, critical ratio (defined as due date divided by processing time), level of inventory, completion times and processing complexity. In each stage, the identical machine's priority is determined based on the information of mean time between failure, mean time to repair, mean time between shutdowns, mean time between maintenance, failure rate and set up time. Figure 1 shows the typical flow shop structure in a manufacturing facility.
So this problem involves determining the mechanism of priority determination of the jobs and machines in an individual stage and how to manage grouping, sequencing and allocating the jobs in the machines at every stage in such a way that the total percentage of over utilization will be minimized and top priority jobs will be processed on top priority machines.
4. Global Journal of Management and Business Research
Volume XVI Issue XI Version I Year ( )
5. Methodology
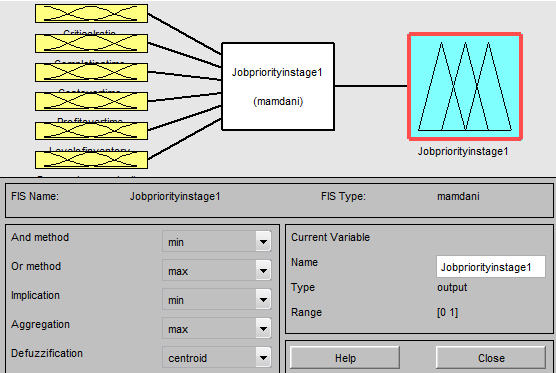
In this study, Mamdani type fuzzy inference method is used because it is intuitive and well suited to human input nonlinear system. Here all the variables are expressed as linguistic variables. In this model, 'minimum' is used for implication stage, 'maximum' is used for aggregation stage and 'centroid' is used for defuzzification. A fuzzy inference system (FIS) is used to identify priority of each job and machine for each individual stage of the hybrid flow shop, using MATLAB Fuzzy Logic Toolbox. To process the top priority job in the top priority machines and minimize the make span, an algorithm is developed for grouping, sequencing and allocating the jobs to the machines at every stage in such a way that the total percentage of over utilization is minimized.
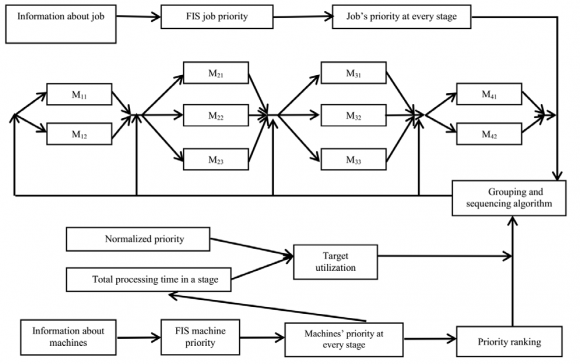
Proposed methodology has been summarized in Figure 2.
6. a) FIS for Job Priority Determination
To incorporate multi objective scheduling, fuzzy priority is calculated by developing a fuzzy inference system using MATLAB fuzzy logic toolbox. Six input variables: critical ratio, profit over time, cost over time, level of inventory, processing complexity and flow times are used in this FIS. The output of this FIS is job priority. In this research, triangular membership function is chosen for all variables, because of its simplicity and computational efficiency. Also there is no speed overshoot, with high steady state accuracy and fast response and recovery. Five membership functions for each input and output are used because higher the number of functions, the greater the number of rules required. The following 35 rules are constructed in the fuzzy inference system to determine the job priority in each machine at the first stage. The weights for each of the input variables are summarized in Table 1. To find out the subsequent stages, five variables are considered: critical ratio, profit over time,
7. b) FIS for Machine Priority Determination
In hybrid flow shop scheduling, machine priority is very important because the highly reliable and available machine should get the high priority during allocation of the top priority job. Reliability is a broad term that focuses on the ability of a product to perform its intended function. Reliability can be defined as the probability that an item will continue to perform its intended function without failure for a specified period of the time under the stated condition. To determine the priority of each machine in every stage, fuzzy inference system is developed which take MTBF, MTTR, MTBS, MTBM, FR and ST as input and machine priority as output. The weights of the input variables are shown in table-1. In this, FIS triangular membership is chosen for each input and output variables. Five membership functions for each input and five membership functions for output are used.
8. c) Grouping and Sequencing Algorithm
After getting the priority of each job and machine for every stage using the two different FIS, the following measures are taken:
Job priority is determined based on their priority value. The job which has the highest priority value has ranked top, second highest priority has ranked second and so on. Similarly, machine priority is determined based on the reliability and availability values. Using this priority value and processing time of each job, the target utilization is calculated with the following equation: Let us suppose the machines have priority R 1 , R 2 , R 3 ,?..,R n Normalized Priority (for machine j), NR j = (R j )/?? ?? ?? ?? ?? =1 ? Target Utilization (for machine j), T j = NR j * TPT where, TPT = Total Processing Time i. Grouping Main principle of this grouping algorithm is to perform the top priority job in the top priority machine. So, the top priority jobs are assigned to the highest priority machine until it satisfies the target utilization.
When it does not satisfy the target utilization, the second highest priority machine is selected and the rest of the jobs are assigned until the target utilization of this machine is satisfied.
If it does not satisfy in the first assignment, the percentage of over utilization for that assignment (U2%) is calculated. The percentage of over utilization (U1%) is also deduced if it is assigned to the highest priority machine with previous assignment. The jobs are assigned to the machine in which percentage of over utilization is minimized and the rest of the jobs are assigned until it satisfies the target utilization of the second highest priority machine.
If it does not satisfy other than the first assignment, the third highest priority machine is selected and the rest of the jobs are assigned to it until it satisfies its target utilization.
If it does not satisfy in the first assignment, the percentage of over utilization for that assignment is calculated. The percentage of over utilization is also deduced if it is assigned to the highest priority machine with previous assignment. The jobs are assigned to the machine in which percentage of over utilization is minimized and the rest of the jobs are assigned until it satisfies the target utilization of the third highest priority machine.
If it does not satisfy other than the first assignment, the fourth highest priority machine is selected and the rest of the jobs are assigned to it until it satisfies its target utilization. Similarly grouping is performed in other stages.
ii. Sequencing Sequencing is determined based on the priority of the job. Highest priority job in the group is assigned first, followed by the second, third and so on. Except for the first stage sequencing, other subsequent sequencing may need to be modified in order to minimize the make span, without hampering the main principle of grouping and sequencing. That is, the higher priority job does not need to wait for the job which has lower priority. It is modified in such a way that if the arrival time of the higher priority job is greater than the completion time of the less priority job in that stage for the same group, the lower priority job should be done first. The complete flow chart for grouping and sequencing algorithm is shown in Figure 4.
9. Global Journal of Management and Business Research
10. Numerical Illustration
The developed algorithm has been coded in C++ programming language with MATLAB fuzzy logic tool box to put the system into practice. For analyzing the performance of the developed algorithm, a case study has been presented. The case study depicted here uses the data collected from a local textile knit composite factory located at Gazipur, Bangladesh to clarify the proposed process. A four stage multiprocessor flow shop is designed, having 2 machines in the first stage, 3 machines in the second and third, and in the final stage, 2 machines. Five jobs have been considered. Here M kj indicates the machine j in stage k. So the jobs in the system pass through four different stages having ten machines. Figure 5 The critical ratio for all the machines in every stage is calculated using the processing times and the due date, based on customer requirements (see Table 2). Table 3 shows the job completion time in each stage, as well as the profit over time and cost over time.
Table 4 depicts the processing complexity and level of inventory for each of the jobs in four stages. The calculated priority of the job using the Fuzzy Inference System is shown in Table 6. Based on this priority, the top priority job in stage 1 is B, followed by D, A, C and E. Similarly, the priority of the jobs in other stages is calculated. Priorities of machines are also determined based on the reliability and availability of the machines found from the FIS. The machine which has the highest priority is ranked as the top priority machine. The other machines follow the same pattern. Then, based on their normalized priority, the target utilization for each machine is determined in Table 7.
11. Results and Discussion
According to the developed algorithm, Table 8 provides the final grouping and sequencing of the jobs in the machines. Accordingly, the jobs should be allocated to ensure the priority of the jobs and machines.
It has been found that both machines should be used in stage 1 to perform the jobs, but in stage 2 only machine 1 is enough. Machine 3 and 1 are required in stage 3, while all the jobs should be performed in machine 1 in the last stage.
Table 5 provides information about the machines' reliability and availability in each of the four stages.
12. Conclusion
Within an organization, scheduling pertains to establishing the timing of the use of specific resources of that organization. It relates to the use of equipment, facilities and human activities. Scheduling decisions are the final step in the transformation process before actual output occurs. Effective scheduling can yield cost savings and increase in productivity. The objectives of scheduling are to achieve trade-offs among conflicting goals, which include efficient utilization of stuff, equipment and facilities, and minimization of customer waiting time, inventories and process times.
In this research, a hybrid flow shop scheduling problem has been analyzed. The uncertainty about the parameters is incorporated by the Fuzzy Inference System. In order to determine the job priority, the parameters considered are critical ratio, profit over time, cost over time, level of inventory, completion time and processing complexity. Machine reliability and availability in each of the stages are characterized by mean time between failure, mean time to repair, mean time between shut down, mean time between maintenance, failure rate and set up time. The ultimate target has been to meet the customers' requirements in terms of meeting due dates and minimizing cost over time. An algorithm is then designed to schedule the grouping and sequencing of the jobs in the respective machines in each of the stages, considering their appropriate priorities, while integrating the production and maintenance planning schemes.
For further research, sensitivity analysis can be performed to enhance the results obtained in this research, and suitable adjustments can be made accordingly. For job priority, some other factors can also be taken into consideration, such as, penalty for not meeting the deadline and level of inventory in the intermediate stages of production. Similarly, for determining the machine priority, other aspects affecting machine reliability and availability can be incorporated to make the schedule more realistic. The model can also be tested by taking actual data from other production systems. For our scheduling purpose, triangular membership function has been used. For other types of models, Gaussian, trapezoidal or sigmoidal membership functions can be used to test the validity of results.
| Input Variables for Job | Weights | Input Variables for Machine | Weights |
| Critical Ratio | 0.95 | MTBF | 1 |
| Flow Time | 0.8 | MTTR | 1 |
| Cost over Time | 1.0 | MTBS | 0.9 |
| Profit over Time | 0.9 | MTBM | 0.9 |
| Level of Inventory | 0.9 | FR | 1 |
| Processing Complexity | 0.5 | ST | 0.8 |
| Job Name | Processing time in Stage 1 (mins) | Processing time in Stage 2 (mins) | Processing time in Stage 3 (mins) | Processing time in Stage 4 (mins) | Due Date (Days) | Critical Ratio in Stage 1 | Critical Ratio in Stage 2 | Critical Ratio in Stage 3 | Critical Ratio in Stage 4 |
| A | 96 | 87 | 137 | 151 | 4 | 0.042 | 0.046 | 0.029 | 0.026 |
| B | 79 | 125 | 102 | 61 | 1 | 0.013 | 0.008 | 0.0098 | 0.016 |
| C | 115 | 139 | 81 | 92 | 6 | 0.052 | 0.043 | 0.074 | 0.065 |
| D | 66 | 109 | 93 | 70 | 3 | 0.045 | 0.028 | 0.032 | 0.043 |
| E | 165 | 82 | 145 | 100 | 5 | 0.03 | 0.061 | 0.034 | 0.05 |
| Total | 521 | 542 | 558 | 474 |
| Completion | Completion | Completion | Completion | |||
| Job | Time in | Time in | Time in | Time in | Cost over | Profit over Time |
| Name | Stage | Stage | Stage | Stage | Time (Tk/hr) | (Tk/hr) |
| 1(mins) | 2(mins) | 3(mins) | 4(mins) | |||
| A | 124 | 115 | 162 | 169 | 85 | 17 |
| B | 99 | 143 | 137 | 86 | 52 | 20 |
| C | 142 | 179 | 105 | 112 | 73 | 16 |
| D | 93 | 131 | 119 | 88 | 68 | 24 |
| E | 181 | 107 | 156 | 133 | 61 | 19 |
| Job Name | Level of Inventory (Kg) | Processing Complexity in Stage 1 | Processing Complexity in Stage 2 | Processing Complexity in Stage 3 | Processing Complexity in Stage 4 |
| A | 2250 | 0.6 | 0.5 | 0.9 | 0.2 |
| B | 1780 | 0.3 | 0.5 | 0.4 | 0.8 |
| C | 1960 | 0.7 | 0.8 | 0.9 | 0.4 |
| D | 2520 | 0.6 | 0.6 | 0.7 | 0.9 |
| E | 2310 | 0.8 | 0.4 | 0.6 | 0.8 |
| Stage | Machine | MTBF | MTTR | MTBS | MTBM | FR (times | ST (mins) |
| No. | No. | (mins) | (mins) | (days) | (days) | per week) | |
| 1 | 1 2 | 1300 1560 | 65 80 | 25 27 | 7 6 | 0.3 0.6 | 70 55 |
| 1 | 850 | 47 | 4 | 3 | 1.1 | 25 | |
| 2 | 2 | 900 | 61 | 4 | 2 | 0.7 | 35 |
| 3 | 770 | 52 | 5 | 3 | 1.3 | 40 | |
| 1 | 1300 | 75 | 6 | 5 | 0.6 | 45 | |
| 3 | 2 | 1160 | 59 | 5 | 4 | 0.9 | 38 |
| 3 | 1190 | 62 | 7 | 4 | 1.1 | 28 | |
| 4 | 1 2 | 1460 1390 | 56 73 | 9 10 | 6 8 | 0.9 1.4 | 25 37 |
| Job Name | Priority | Priority | Priority | Priority |
| (Stage 1) | (Stage 2) | (Stage 3) | (Stage 4) | |
| A | 0.56 | 0.567 | 0.507 | 0.524 |
| B | 0.628 | 0.526 | 0.526 | 0.539 |
| C | 0.511 | 0.513 | 0.504 | 0.501 |
| D | 0.577 | 0.529 | 0.541 | 0.549 |
| E | 0.509 | 0.469 | 0.476 | 0.492 |
| Modeling and Scheduling of Multi-Stage and Multi-Processor Flow Shop | ||||
| 2016 | ||||
| Year | ||||
| ( ) A | ||||
| Stage No. | Machine No. | Priority | Normalized Priority | Target Utilization |
| 1 | 1 2 | 0.523 0.526 | 0.49857 0.50143 | 259.755 261.245 |
| 1 | 0.479 | 0.35040234 | 189.918 | |
| 2 | 2 | 0.458 | 0.33504 | 181.59168 |
| 3 | 0.43 | 0.31456 | 170.49 | |
| 1 | 0.479 | 0.3352 | 187.0416 | |
| 3 | 2 | 0.46 | 0.321903 | 179.622 |
| 3 | 0.49 | 0.342897 | 191.337 | |
| 4 | 1 2 | 0.508 0.455 | 0.52751872 0.47248188 | 250.04361 223.95639 |
| V. | ||||
| Stage No. | Machine No. (sequenced based | Job Name |
| on priority) | ||
| 1 | 2 (0.526) 1 (0.523) | B,C D,A,E |
| 1 (0.479) | E,D,C,B,A | |
| 2 | 2 (0.458) | - |
| 3 (0.43) | - | |
| 3 (0.49) | E | |
| 3 | 1 (0.479) | D,C,B,A |
| 2 (0.46) | - | |
| 4 | 1 (0.508) 2 (0.455) | E, D,C,B,A - |
| VI. |